AI 算力扩展的三大瓶颈:Dylan Patel 深度分析
💡 小编点评:算力扩展瓶颈深度分析,AI 基础设施投资参考
📌 核心要点
- 瓶颈 1: 电力供应 - 数据中心耗电增速超过电网扩容能力
- 瓶颈 2: 芯片封装 - CoWoS 先进封装产能不足
- 瓶颈 3: 网络带宽 - GPU 集群通信成为训练瓶颈
🔍 背景:为什么算力扩展如此重要
AI 模型的规模仍在快速增长:
2023: GPT-4 ~1T params2024: Claude-3 ~2T params2025: Gemini-2 ~5T params2026: 预期 10T+ params但算力扩展不是线性的,存在明显的边际递减效应。Dylan Patel 在访谈中指出了三个关键瓶颈。
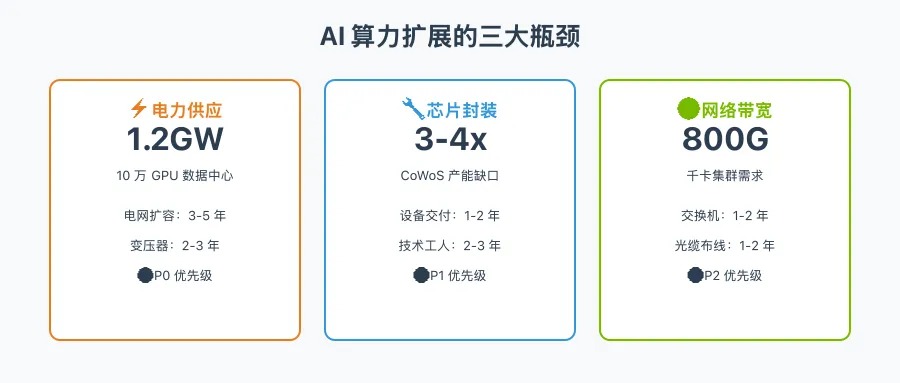
🏗️ 瓶颈一:电力供应
问题描述
单个 H100 GPU 功耗:700W单个 GB200 NVL72 机柜功耗:120kW大型数据中心 (10 万 GPU) 功耗:1.2GW
相当于 100 万户家庭的用电量具体挑战
| 挑战 | 描述 | 解决时间 |
|---|---|---|
| 电网容量 | 现有电网无法支撑新建数据中心 | 3-5 年 |
| 变压器短缺 | 高压变压器交付周期 2-3 年 | 2-3 年 |
| 可再生能源 | 太阳能/风能不稳定,需要储能 | 5-10 年 |
| 核能审批 | 小型模块化反应堆 (SMR) 审批缓慢 | 5-8 年 |
投资方向
- 核能: SMR 技术 (NuScale, TerraPower)
- 储能: 锂电池、液流电池、压缩空气
- 电网升级: 高压输电、智能电网
- 能效优化: 液冷技术、余热回收
🏗️ 瓶颈二:芯片封装
问题描述
NVIDIA H100 需要 CoWoS 先进封装单颗 H100 封装时间:4-6 周台积电 CoWoS 产能:月产 5-7 万片 (2025)需求:月产 15-20 万片
缺口:3-4 倍具体挑战
| 挑战 | 描述 | 解决时间 |
|---|---|---|
| 封装设备 | 贴片机、键合机交付周期长 | 1-2 年 |
| 技术工人 | 封装工艺需要熟练技师 | 2-3 年 |
| 材料供应 | 基板、焊球等原材料短缺 | 1-2 年 |
| 良率提升 | CoWoS 良率~80%,需要提升到 95%+ | 1-2 年 |
投资方向
- 封装设备: ASMPT, K&S, BESI
- 封装材料: 基板、焊球、导热材料
- 替代技术: Chiplet、3D 堆叠
- 本土产能: 中国大陆封装厂 (长电科技、通富微电)
🏗️ 瓶颈三:网络带宽
问题描述
GPU 训练集群通信模式:All-Reduce单次迭代通信量:模型参数 x 2100B 参数模型:200GB/次迭代千卡集群:需要 800Gbps+ 互联带宽
当前主流:400Gbps InfiniBand下一代:800Gbps/1.6Tbps InfiniBand具体挑战
| 挑战 | 描述 | 解决时间 |
|---|---|---|
| 交换机端口 | 800G 交换机端口供应不足 | 1-2 年 |
| 光缆布线 | 数据中心内部光缆复杂度高 | 1-2 年 |
| 协议优化 | NCCL、RCCL 等通信库优化 | 持续 |
| 拓扑设计 | 胖树、Dragonfly 等拓扑优化 | 持续 |
投资方向
- 网络设备: Mellanox (NVIDIA), Arista, Cisco
- 光模块: 800G/1.6T 光模块厂商
- 通信芯片: Broadcom, Marvell
- 软件优化: NCCL 优化、通信压缩
📊 投资优先级排序
根据 Dylan Patel 的分析,投资优先级如下:
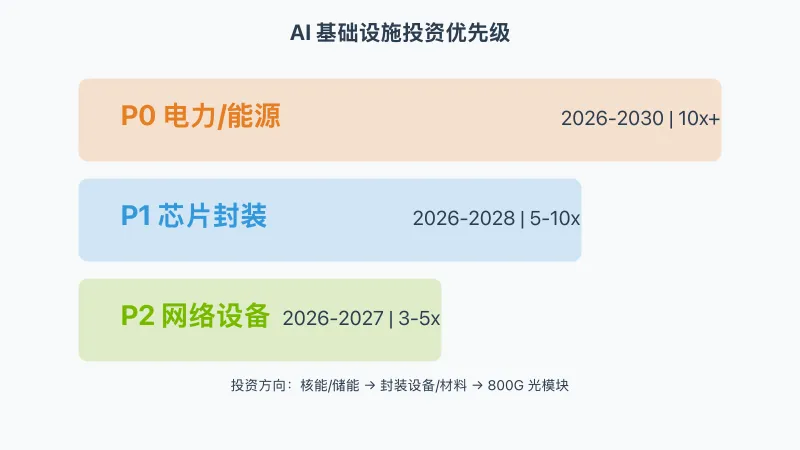
| 优先级 | 领域 | 时间窗口 | 预期回报 |
|---|---|---|---|
| P0 | 电力/能源 | 2026-2030 | 10x+ |
| P1 | 芯片封装 | 2026-2028 | 5-10x |
| P2 | 网络设备 | 2026-2027 | 3-5x |
| P3 | AI 应用 | 2027-2030 | 不确定 |
💡 对投资者的建议
为什么基础设施优于模型厂商
- 确定性更高: 无论哪家模型厂商胜出,都需要电力、封装、网络
- 壁垒更深: 电网、封装厂、网络设备建设周期长,竞争格局稳定
- 价值捕获: 历史经验表明,基建环节捕获的价值往往高于应用环节
具体投资标的
电力/能源 (P0):
- 核能 SMR: NuScale, TerraPower
- 储能:锂电池、液流电池厂商
- 电网设备:高压输电、智能电网
芯片封装 (P1):
- 封装设备:ASMPT, K&S, BESI
- 封装材料:基板、焊球、导热材料
- 本土产能:长电科技、通富微电
网络设备 (P2):
- 交换机:Mellanox (NVIDIA), Arista
- 光模块:800G/1.6T 厂商
- 通信芯片:Broadcom, Marvell
💡 对开发者的启示
理解这些瓶颈有助于判断:
推理成本下降速度
- 受电力和封装限制,2026-2027 年成本下降可能放缓
- 建议在成本敏感型项目中锁定长期 API 合约
模型规模增长速度
- 受网络和电力限制,10T+ 模型可能推迟到 2027-2028 年
- 当前应关注模型优化技术 (MoE、量化、蒸馏)
技术路线选择
- MoE 架构:减少激活参数,降低推理成本
- 量化技术:4bit/8bit 量化,减少内存占用
- 蒸馏技术:小模型学习大模型,降低部署成本
💡 小编总结
Dylan Patel 的核心观点是:AI 竞赛的本质是基础设施竞赛。谁能先解决电力、封装、网络这三个瓶颈,谁就能在下一轮 AI 竞争中占据优势。
对于投资者来说,不要只盯着 AI 模型厂商,更要关注:
- 能源公司 (尤其是核能、储能)
- 半导体设备/材料 (尤其是封装环节)
- 网络设备商 (尤其是 800G+ 光模块)
对于开发者来说,理解这些瓶颈有助于判断:
- 推理成本下降速度 (受电力和封装限制)
- 模型规模增长速度 (受网络和电力限制)
- 技术路线选择 (MoE、量化、蒸馏等优化方向)
关键判断:2026-2028 年是 AI 基础设施投资黄金窗口期。瓶颈越严重,投资机会越大。
📚 参考资料
- Dylan Patel — Deep dive on the 3 big bottlenecks to scaling AI compute - Dwarkesh Podcast
- NVIDIA GB200 NVL72 Technical Specifications
- TSMC CoWoS Capacity Update 2025
- IEA Global Energy Review 2025
- Mellanox InfiniBand Roadmap 2026
更多同类文章
Karpathy 2025 LLM 年度总结深度解读 2025 年是 LLM 领域"强劲且充满事件"的一年。Karpathy 用"paradigm changes"(范式转变)来定义这一年的关键突破。值得注意的是他的措辞:"personally notable and mildly surprising"(个人显著且轻微惊讶)。这种克制的表达背后,是对技术发展的深刻理解:真正的范式转移往往不是戏剧性的"从 0 到 1",而是在既有框架内的重构和优化。
DeepSeek-V4 发布前瞻:架构升级与推理成本新突破 DeepSeek-R1 于 2025 年初发布,开创了开源推理模型的先河。但 AI 领域迭代极快,R1 的使命已经完成:
龙虾经济学:当 AI 智能体改写经济规则 从 MIT 研究到 Deer-Flow2,解读智能体如何摧毁交易成本、改写经济规则。
AI Token 经济学:GTC 2026 深度解读 从 GPU 工厂、Token 输出到 OpenClaw 生态,解读 GTC 2026 背后的 AI 基础设施逻辑。