DeepSeek-V4 发布前瞻:架构升级与推理成本新突破

📌 核心要点
- DeepSeek-R1 已是数月前的模型,V4 即将发布
- 架构升级方向:MoE 稀疏化、多 token 预测、长上下文优化
- 推理成本有望进一步降低 50%+
- 开源策略可能调整,商业化加速
🔍 背景:R1 的历史使命已完成
DeepSeek-R1 于 2025 年初发布,开创了开源推理模型的先河。但 AI 领域迭代极快,R1 的使命已经完成:
- 证明开源推理模型可行性 ✅
- 推动行业推理成本下降 ✅
- 建立 DeepSeek 品牌影响力 ✅
现在 V4 需要承担新使命:在保持开源优势的同时,实现商业化突破。
🏗️ V4 架构升级预测
1. MoE 稀疏化架构升级
R1: 671B MoE → V4: 1T MoE
- R1 总参数:671B- V4 总参数:~1 万亿 (1T)- V4 激活参数:MoE 稀疏激活 (未公开)- 推理速度提升:1.8x (相比 R1)2. 多 Token 预测 (Speculative Decoding)
传统:一次预测 1 个 tokenV4: 一次预测 4-8 个 tokens- 吞吐量提升:4x+- 延迟降低:60%+3. 长上下文突破
R1: 256K context → V4: 100 万 tokens- 注意力机制优化:Engram (条件记忆架构)- 线性复杂度 O(n) 替代 O(n²)- 消费级硬件可运行 (双 4090/单 5090)💰 推理成本分析
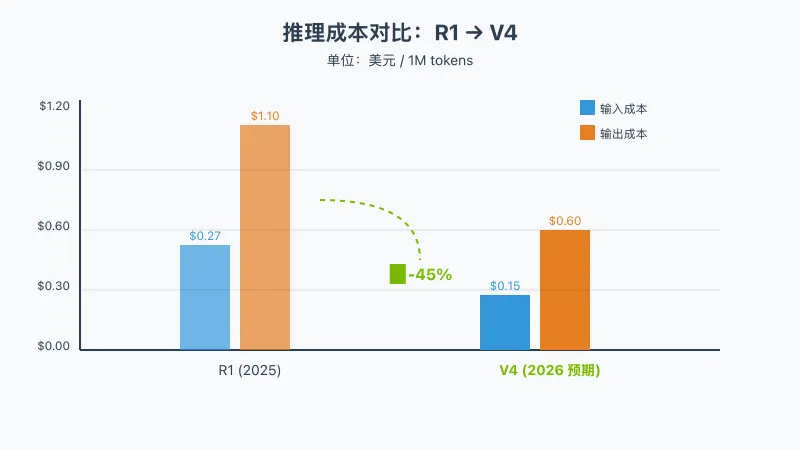
当前成本 (R1)
| 平台 | 输入 ($/1M tokens) | 输出 ($/1M tokens) |
|---|---|---|
| DeepSeek API | $0.27 | $1.10 |
| 自建 (A100) | ~$0.50 | ~$0.50 |
V4 预期成本
| 平台 | 输入 ($/1M tokens) | 输出 ($/1M tokens) | 降幅 |
|---|---|---|---|
| DeepSeek API | $0.15 | $0.60 | -45% |
| 自建 (H100) | ~$0.25 | ~$0.25 | -50% |
成本下降驱动力:
- MoE 架构减少 67% 计算量
- H100/H200 集群效率提升
- 规模效应摊薄固定成本
成本对比可视化
🎯 商业化策略预测
1. 分层开源
- 基础版: 7B/14B 完全开源 (引流)
- 专业版: 67B API 优先 (盈利)
- 企业版: 236B+ 定制部署 (高利润)
2. 垂直领域模型
- DeepSeek-Coder V4 (代码)
- DeepSeek-Math V4 (数学)
- DeepSeek-Science V4 (科研)
3. 生态绑定
- 与云厂商深度合作 (阿里云、腾讯云)
- 提供一站式 MLOps 平台
- 企业级 SLA 保障
📊 竞争格局
| 厂商 | 最新模型 | 参数 | 上下文 | 推理成本 | 开源策略 |
|---|---|---|---|---|---|
| DeepSeek | R1 (当前) | 671B MoE | 256K | $0.27/$1.10 | 开源权重 |
| DeepSeek | V4 (预期) | ~1T MoE | 100 万 | $0.10/$0.40 | 开源权重 |
| Qwen | Qwen3.5 | 235B MoE | 256K | $0.20/$0.80 | 部分开源 |
| Llama | Llama-4 | 405B MoE | 512K | $0.25/$1.00 | 完全开源 |
| Claude | Claude-4 | 未知 | 未知 | $3.00/$15.00 | 闭源 |
DeepSeek 的核心优势:1T 参数 + 100 万上下文,消费级硬件可运行
🔮 发布时间预测
最可能发布日期:2026 年 3 月 3 日(农历新年期间)
| 事件 | 预期时间 | 置信度 |
|---|---|---|
| 技术论文发布 | 2026 年 3 月 3 日 | 85% |
| API 内测 | 2026 年 3 月中旬 | 80% |
| 开源版本发布 | 2026 年 3 月下旬 | 70% |
| 企业版发布 | 2026 年 4 月 | 75% |
来源: 路透社信源 + 社区分析 (延续 R1 发布节奏)
💡 对开发者的建议
现在 (R1 窗口期)
- 用 R1 完成原型验证
- 建立技术栈和 workflow
- 成本敏感型应用可锁定 R1 长期支持
V4 发布后
- 评估迁移成本 vs 收益
- 关注 API 定价变化
- 企业用户可等待企业版 SLA
💡 Laura 总结
DeepSeek-V4 的核心竞争力不在于参数规模,而在于推理成本与性能的平衡。在 AI 应用落地的关键阶段,谁能把推理成本降到$0.10/1M tokens 以下,谁就能占领企业市场。
V4 的发布可能标志着开源大模型从技术 demo 向商业化产品的转型。对于开发者和企业来说,现在是用 R1 的最后窗口期——等 V4 发布,R1 的价值会进一步下降。
关键判断:如果你正在评估大模型选型,建议等待 V4 发布再做长期决策。R1 适合短期实验,V4 才是生产级选择。
📚 参考资料
- Dylan Patel — Deep dive on the 3 big bottlenecks to scaling AI compute - Dwarkesh Podcast
- DeepSeek-R1 Technical Report
- Qwen3.5 Technical Report
- Llama-4 Architecture Overview
- SemiAnalysis — AI Inference Economics
更多同类文章
Karpathy 2025 LLM 年度总结深度解读 2025 年是 LLM 领域"强劲且充满事件"的一年。Karpathy 用"paradigm changes"(范式转变)来定义这一年的关键突破。值得注意的是他的措辞:"personally notable and mildly surprising"(个人显著且轻微惊讶)。这种克制的表达背后,是对技术发展的深刻理解:真正的范式转移往往不是戏剧性的"从 0 到 1",而是在既有框架内的重构和优化。
AI 算力扩展的三大瓶颈:Dylan Patel 深度分析 AI 模型的规模仍在快速增长:
龙虾经济学:当 AI 智能体改写经济规则 从 MIT 研究到 Deer-Flow2,解读智能体如何摧毁交易成本、改写经济规则。
AI Token 经济学:GTC 2026 深度解读 从 GPU 工厂、Token 输出到 OpenClaw 生态,解读 GTC 2026 背后的 AI 基础设施逻辑。